
互联网上肯定会存在大量的重复内容网页,这时需要有一个过滤的机制,主要目的是处理文本内容的去重、过滤和聚类,而百度指纹算法是属于文章质量度的一种算法。那么百度指纹算法是什么?指纹系统是如何识别的?
一、对原创内容的定义
从SEO角度,创作原创文章的定义前提条件是内容具备可读性、通俗易懂,并且文字与搜索引擎其他相关网页内容保持独立一致性,即可满足原创的要求。这里注意一个点,优质内容不一定是内容原创,也可以是内容聚合。
我们可以常常看到百度百科的各种词条里面的内容,几乎都是来源于参考作证里面的资料。单纯说原创,很多百科词条的内容原创部分不会超过1%,更多的还是将有价值的优质内容去进行聚合。而搜索引擎所强调的并不是一味的原创,而是优质,更多的是内容对用户要有所帮助,但并不一定要有原创独一无二的内容来供给。
二、百度指纹算法是什么
简单来说搜索引擎指纹算法就和人的指纹一样,看起来这个手指是差不多的,但是实际上每一个人的手指都有一个独一无二的指纹,而我们所看到的网页也是一样的。不少网页内容其实都是差不多的,但是每一个网页搜索引擎抓取以后都会保存,然后建立一个指纹,可以理解为唯一标识符,而这个算法最大的好处就是可以通过这个唯一标识别符来计算网页的重复。
搜索引擎网页指纹技术在百度百科中的解释是:提取一个信息的特征,通常是一组词或者一组词+权重,然后根据这组词调用特别的算法,例如MD5,将之转化为一组代码,这组代码就成为标识这个信息的指纹。搜索引擎在抓取内容之后,会首先剔除掉文章中的一些非特征信息关键词,比如:你、我、他等称谓;而且、但是等连接词;哦、呢、吧等语气词。这些词对于信息标识是没有帮助的,然后就是对文字信息的提取与处理,经过一系列复杂的算法流程。
三、常见的搜索引擎指纹算法
最简单的指纹构造方式就是计算文本的md5或者sha哈希值,除非输入相同的文本,否则会发生“雪崩效应”,极小的文本差异通过md5或者sha计算出来的指纹就会不同(发生冲撞的概率极低),那么对于稍加改动的文本,计算出来的指纹也是不一样。
因此,一个好的指纹应该具备如下特点:
1、指纹是确定性的,相同的文本的指纹是相同的;
2、指纹越相似,文本相似性就越高;
3、指纹生成和匹配效率高。
业界关于文本指纹去重的算法众多,如k-shingle算法、google提出的simhash算法、Minhash算法、top k最长句子签名算法等。搜索引擎指纹算法和一般的算法不一样的地方在于它是针对网页集合来进行判断的,不像网页去重这种算法是页面与页面之间判断。而指纹是通过大数据进行集合判断,最后通过唯一标识符号判断网页内容是否原创。
四、内容型网页文本指纹算法
从前文可以看出,指纹识别算法是实现指纹识别的关键,它直接决定了识别率的高低,是指纹识别技术的核心。特别是类似新闻类、小说类网页在转载或者盗版过程中,文字的个数、顺序上一般都保持一致,当然不排除个别字错误或者少一个字的情况。
指纹生成的过程主要包括将文本全部转换成拼音、截取每个字拼音的首字母、统计该粒度内字母的频率分布、通过和参考系比较,将结果进行归一化、按字母序,将数字表征转换成数字。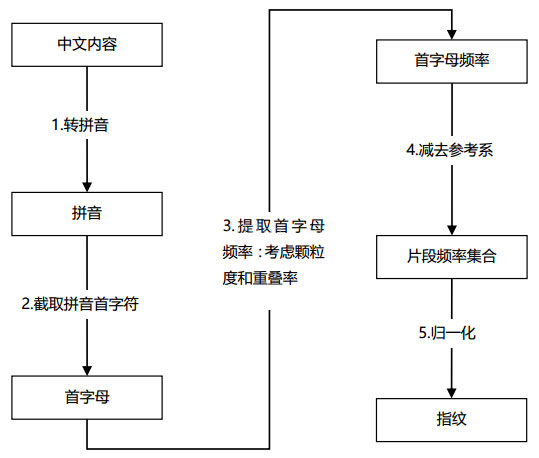
五、指纹系统结构
指纹追踪系统主要由爬虫系统、指纹生成系统、指纹存储、指纹查询和比对、数据分析、后台管理系统等几个主要模块构成。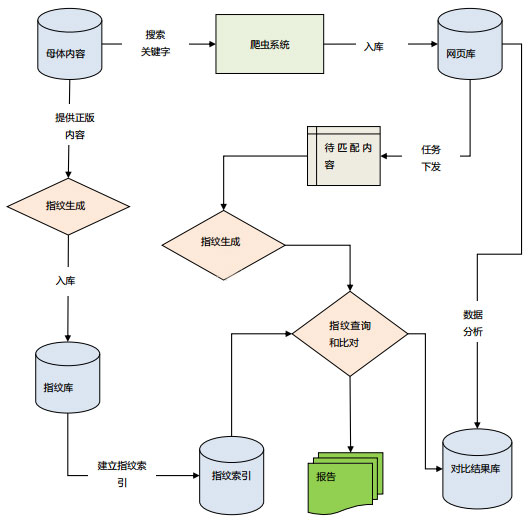
写在结尾:想做好网站收录,一定要了解去重算法和指纹算法,只有这样才能做好原创内容,帮助网站促进收录,提升排名。另外对于对一个新的网页,搜索引擎会有一个阈值,当你的网页质量达到了这个阈值,那么这个页面才会被收录,进而被索引参与排名展现。
百度指纹算法是什么?指纹系统是如何识别的?
4353
0
版权声明:除非特别标注,否则均为本站原创文章,转载时请以链接形式注明文章出处。






还木有评论哦,快来抢沙发吧~