
TF-IDF是两个统计量的乘积,词频和逆文档频率。有多种方法可以确定这两种统计数据的准确值,主要是定义关键字或短语在文档或网页中的重要性的公式。本文我们详细讲下TF-IDF是什么意思?TF-IDF算法如何计算?
一、TF-IDF是什么意思
TF-IDF全名为:Term Frequency-Inverse Document Frequency,是一种决定单词对于一份文件重要程度的衡量手法,也是信息检索与数据挖掘的常用加权技术。它由两个部分组成:词频(term frequecny, tf)与逆向文件频率(inverse document frequency, idf)。
TF-IDF是一种统计方法,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。
1、词频(term frequecny, tf)
词频,顾名思义就是单词出现在一份文件的频率。如果某一单词在一份文件当中出现的次数越多,我们会直觉地认为它越是重要。然而我们不能只以“次数”来衡量,必须考虑文件的篇幅。因此我们需要进行正规化,将次数再除以文件长度,于是有了以“频率”来衡量单词重要性的计算方式: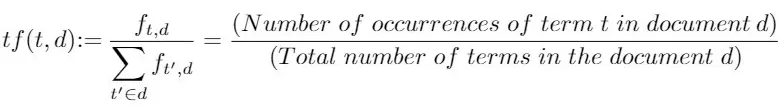
在以上定义中, 表示单词 t 在文件 d 当中的次数。
2、逆向文件频率(inverse document frequency, idf)
有许多单词,其词频非常高,却不具重要性,如 a/an、 the 等停用词(stop words)。因此由将单词出现的次数正规化而得的词频还不足以衡量单词在文本中的重要程度,我们仍需要考虑单词对于语料库的重要程度,其计算方式如下: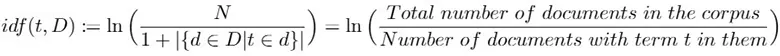
在上述定义当中, D 表示语料库,其元素为文件 d 。而分母加上1则是为了避免由于单词不在语料库中而导致分母为零(division-by-zero)的状况,是一种well-defined的表现。
借由对数 ln() 严格递增的特性,我们可以直言:如果某个单词越是集中出现在某几份文件中,则 idf 就越大,其对于整个语料库而言就越重要。反之,当某个单词在大量文件中都出现,idf 就越小,我们会认为这个单词重要性一般。
3、TF-IDF加权计算
当我们将 tf 和 idf 相乘起来,就可以反映出一个单词在语料库中对于一份文件有多么重要。于是整合起来定义计算公式如下: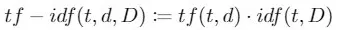
二、TF-IDF算法步骤
1、计算词频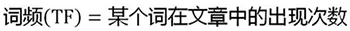
考虑到文章有长短之分,为了便于不同文章的比较,进行“词频”标准化。
2、计算逆文档频率
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
3、计算TF-IDF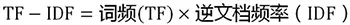
可以看到,TF-IDF与一个词在文档中的出现次数成正比,与该词在整个语言中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
三、TF-IDF算法举例一
有很多不同的数学公式可以用来计算TF-IDF,这个的例子以上述的数学公式来计算。
1、词频 (TF) 是一词语出现的次数除以该文件的总词语数。假如一份文档的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。
2、一个计算文件频率 (IDF) 的方法是文件集里包含的文件总数除以测定有多少份文件出现过“母牛”一词。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。
3、最后的TF-IDF的分数为0.03 * 4=0.12。
四、TF-IDF算法举例二
例如有网民在搜索引擎上搜索“水果”这个名词,搜索引擎给排名前五的网站有5个,以下5条内容你觉得哪条会排在第一名?
1、内容1:水果有水果,水果,水果,水果,水果
2、内容2:水果有苹果,桃子,西瓜,菠萝,梨子
3、内容3:蔬菜都很好吃,我最爱吃茄子了
4、内容4:苹果,梨子都是很好吃的水果
5、内容5:好吃的水果有西瓜,苹果,葡萄,其他水果还有菠萝,猕猴桃
如果按照TF-IDF算法得出的结果,内容5是第一名,内容2是第二名,4是第三名,1跟3相关度不够,没有排名。
以上是精简后的TF-IDF算法举例,TF-IDF算法运行起来比这个要复杂的多,本文只是让大家明白TF-IDF算法的基本运行原理。当有TF(词频)和IDF(逆文档频率)后,将这两个词相乘,就能得到一个词的TF-IDF的值。某个词在文章中的TF-IDF越大,那么一般而言这个词在这篇文章的重要性会越高,所以通过计算文章中各个词的TF-IDF,由大到小排序,排在最前面的几个词,就是该文章的关键词。




评论列表